Latency-budget routing: how to stop SLA breaches before they happen
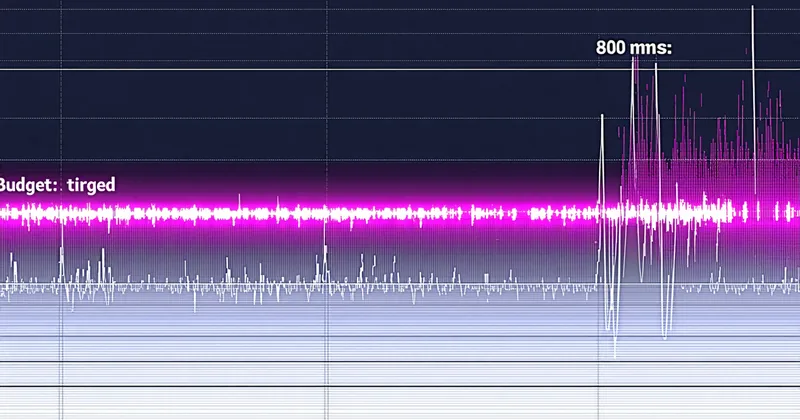
Declare a latency budget in your routing policy. Kamiwaza evaluates real-time p95 per endpoint and fails over before your application sees a timeout.
Read articleArchitecture analysis on LLM routing policy design, private GPU infrastructure trade-offs, tenant isolation patterns, and cost-per-token benchmarks across Anthropic, OpenAI, and Bedrock.
Declare a latency budget in your routing policy. Kamiwaza evaluates real-time p95 per endpoint and fails over before your application sees a timeout.
Read articleWe ran 100,000 requests across Claude Haiku, GPT-4o-mini, and Bedrock Llama 3 Instruct. The latency distributions at p50, p95, and p99 tell a different story than the marketing pages.
Read articleThree patterns for giving each customer their own model policy in a shared inference gateway: per-tenant model allowlists, audit bucket isolation, and per-tenant rate limits.
Read articlePushing safety controls into each application creates fragmentation and audit gaps. Here's why the model gateway is the right enforcement point for data class restrictions and redaction policies.
Read articleNot every workload belongs on-prem. Not every workload is safe on a managed API. We walk through the four questions platform teams should answer before deciding.
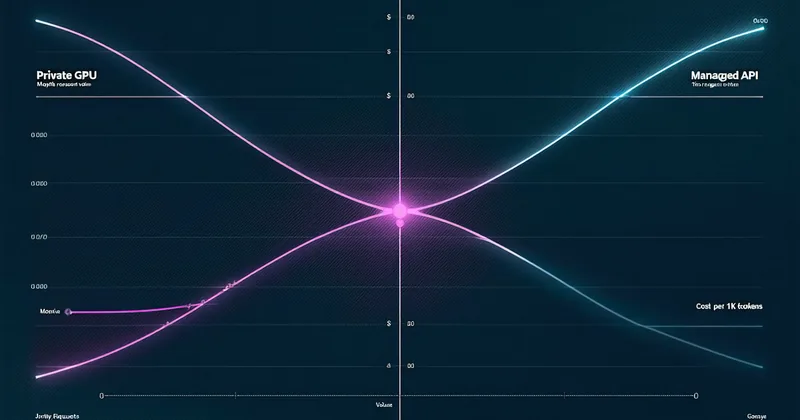
Read articleA cost-per-token analysis across private GPU (Llama 3.1 70B on A100), Anthropic Claude Haiku, and AWS Bedrock Llama 3. The break-even volume is lower than most teams expect.
Read article