The AI model gateway for enterprise infrastructure
One control plane for private GPU nodes (vLLM, TGI, TensorRT-LLM), managed APIs (Anthropic, OpenAI, Bedrock, Vertex AI), and internal fine-tunes. Declarative routing policies. Full per-request audit trail.
Architecture
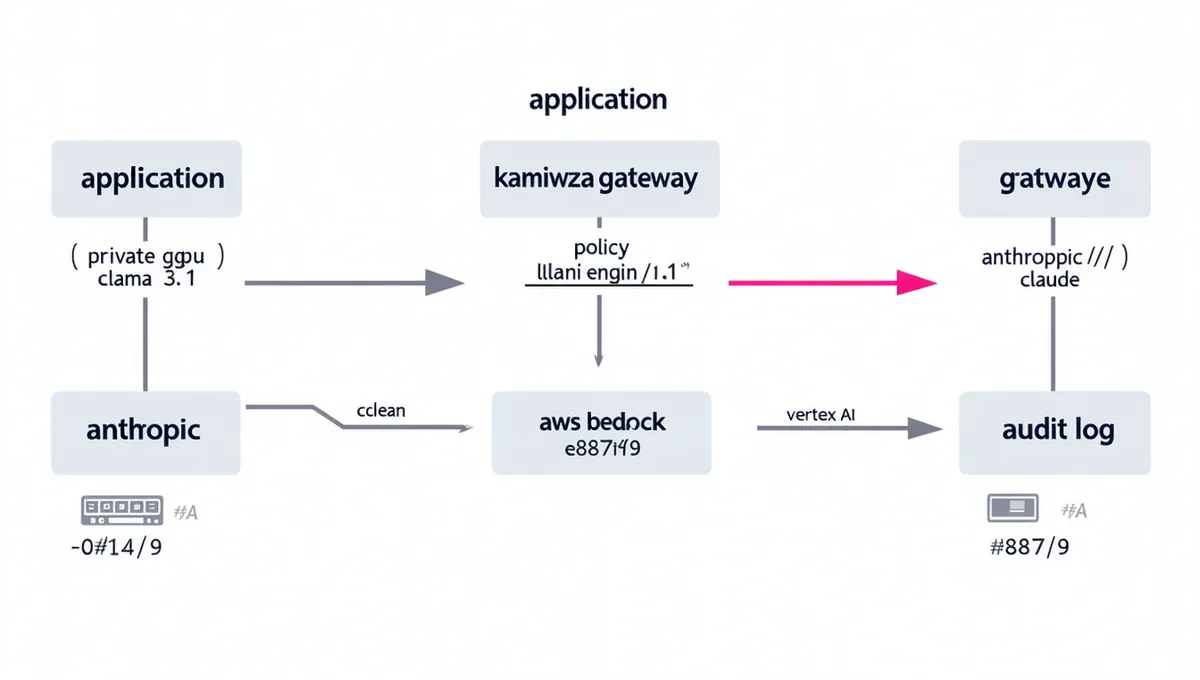
Request lifecycle
Every inbound request hits a single /v1/route endpoint. Kamiwaza extracts tenant identity, data class, and request metadata, then evaluates the routing policy tree. The winning rule determines which endpoint receives the forwarded request.
Policy evaluation engine
Rules are evaluated in declaration order. Each rule is a match/action pair: match on tenant ID, data class, user role, latency budget, or cost cap; route to the named endpoint. First match wins.
Audit log pipeline
Every request generates a structured audit record: timestamp, tenant, data class, matched policy, selected endpoint, latency, cost attribution. Streamed to your configured storage (S3, GCS, or Kamiwaza hosted).
Supported endpoint types
| Endpoint type | Connection | Auth | Data stays in your VPC |
|---|---|---|---|
| Private GPU (self-hosted) | VPC Peering / PrivateLink | Bearer token | Yes |
| Anthropic Claude | HTTPS / public | API key | No (Anthropic's infra) |
| OpenAI GPT-4/3.5 | HTTPS / public | API key | No (OpenAI's infra) |
| AWS Bedrock | VPC Endpoint / HTTPS | IAM / STS | Yes (with VPC endpoint) |
| GCP Vertex AI | Private Service Connect | Service Account | Yes (with PSC) |
| Azure OpenAI | Private Endpoint / HTTPS | Azure AD / API key | Yes (with Private Endpoint) |
Kamiwaza is not a model provider. We route to your existing keys — you retain your existing agreements with each provider. Kamiwaza never touches your provider billing.
Routing policy language
YAML-first policy language. Express tenant isolation, data class guards, latency budgets, and cost caps as declarative rules. Store them in git, review them in PRs, audit them in logs.
# Full routing policy example
version: v1
rules:
# PII data always stays on-prem
- match:
data_class: pii-restricted
route_to: private-gpu
# Tenant-specific model allowlist
- match:
tenant: enterprise-acme
latency_budget_ms: "<400"
route_to: anthropic
# Cost-capped fallback
- match:
cost_cap_per_1k: "<0.002"
route_to: bedrock
- default:
route_to: anthropicObservability built in
Per-request latency
p50, p95, p99 latency by endpoint. Identify which model is lagging and trigger failover rules.
Cost attribution by tenant
Token costs mapped to tenant IDs. Know exactly which customer is spending on which model.
Model usage breakdown
Request volume and token usage by endpoint, model, and policy rule. Drive capacity planning.
Policy evaluation audit log
Every routing decision logged: matched rule, evaluated conditions, selected endpoint. Full compliance trail.